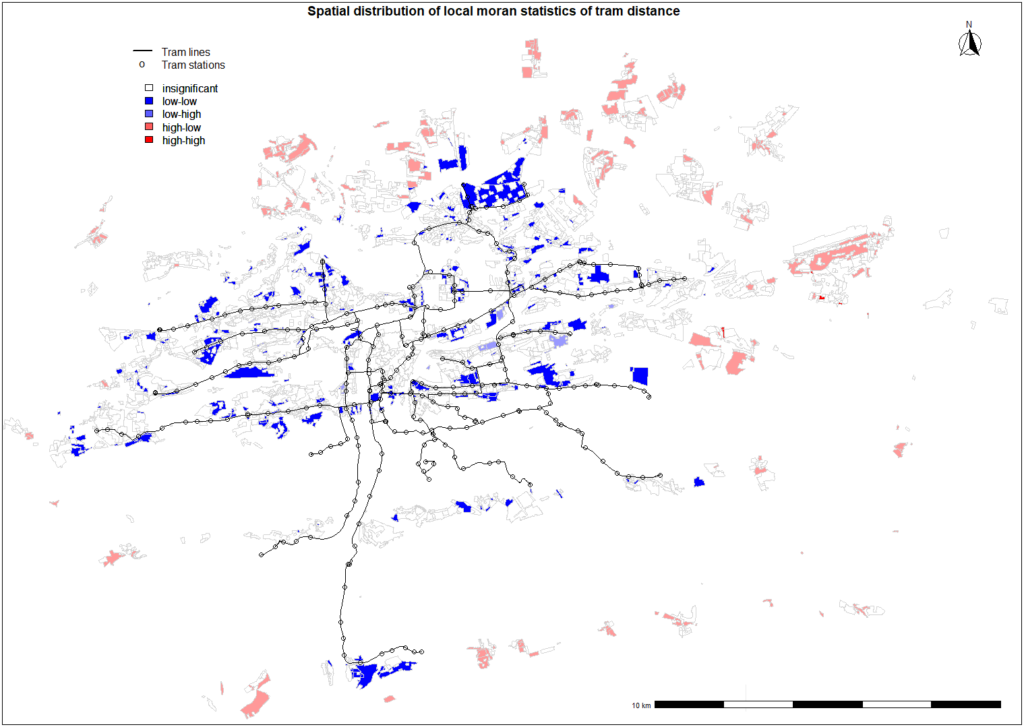
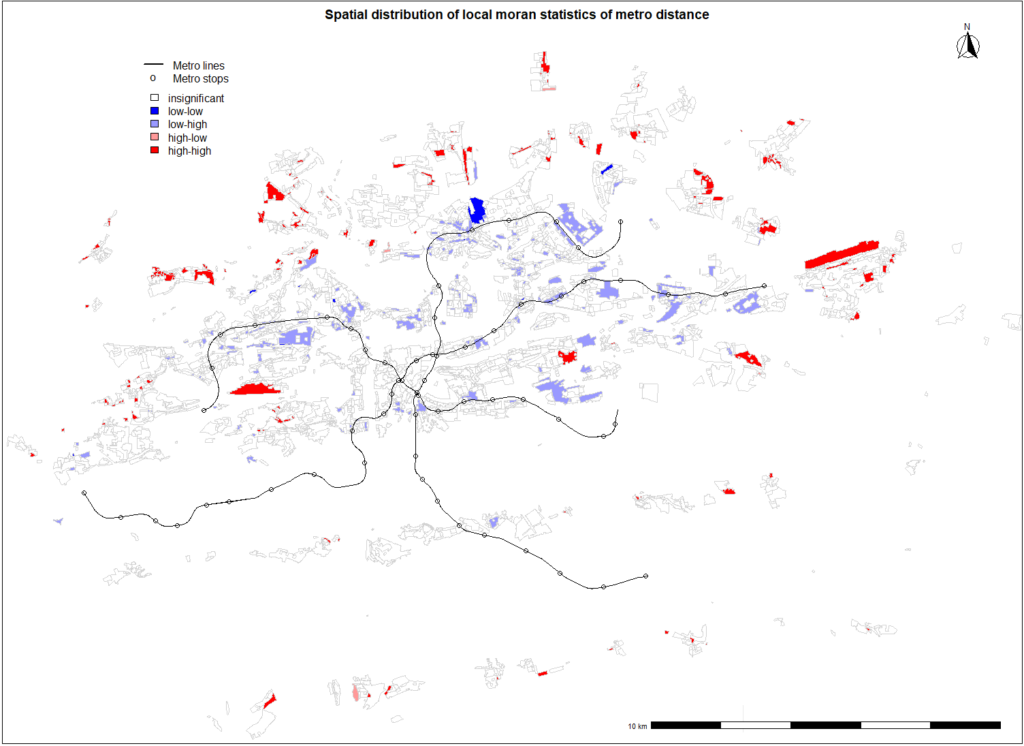
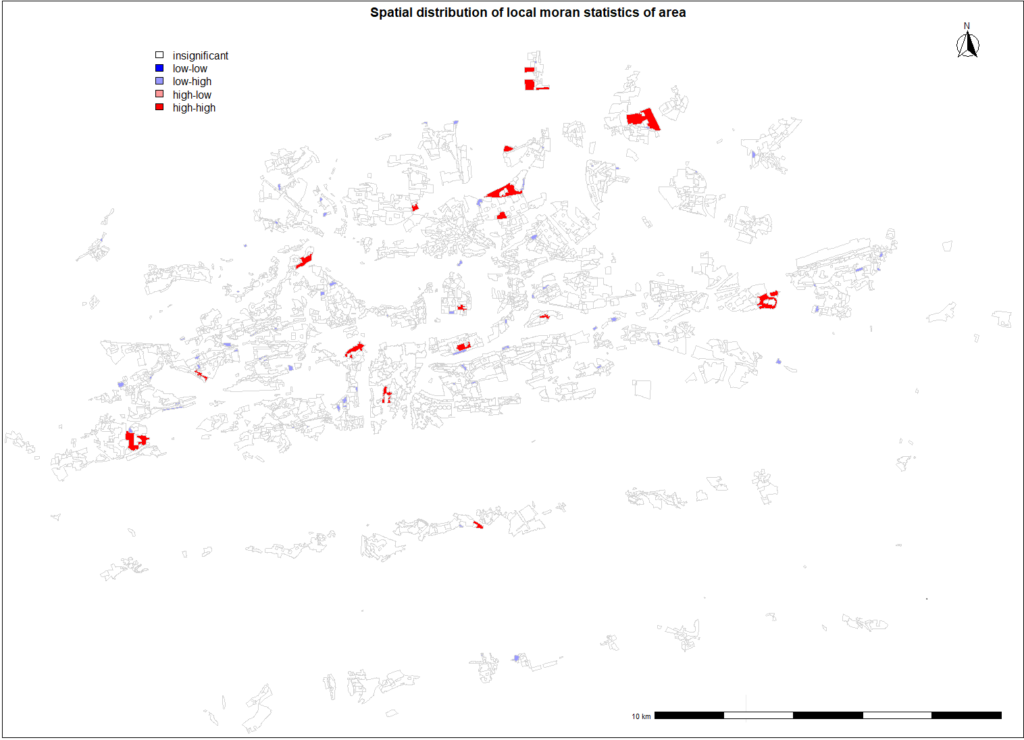
As mentioned above in the report, our final model is gamma distributed model stated above.
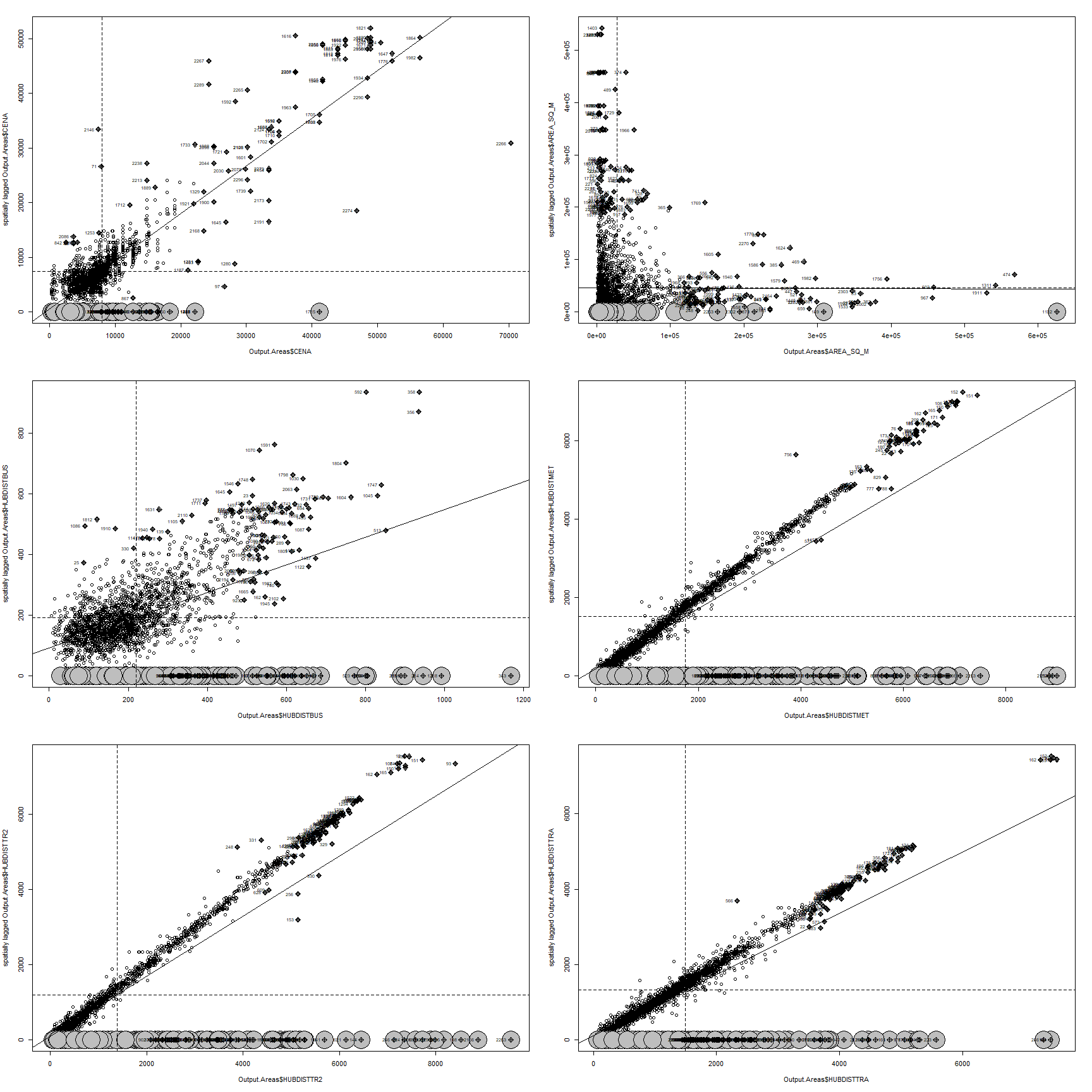
The diagnostics plot of final model are depicted on figure below:
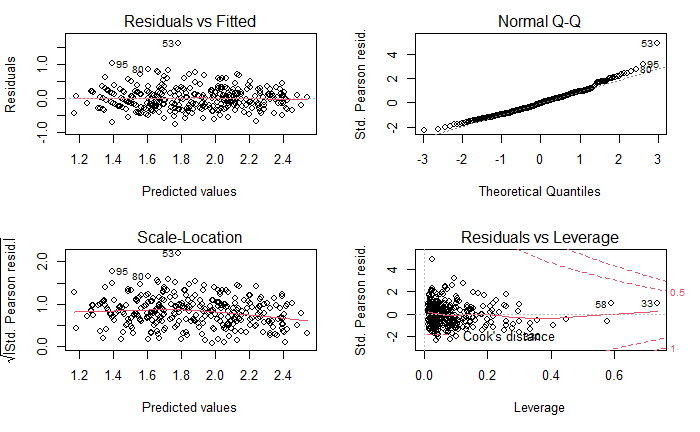
Compared with diagnostic plot of classical general linear model, we observe differences. The outlying observations are different, however none of these outliers lies in the Cook´s distance region. In the Residual vs Fitted plot we got rid of the pattern when the observations were clustered in lines, now they seems to be more scattered.
On the Normal Q-Q plot, we can see outlying observation number 53. We might have slightly improve the model fit by removing this point however as we are not sure if it caused by measuring error, we have decided to leave it there.
On the Scale location plot we can observe that the red line is more horizontal which indicates better fit of the model compared with the final model in question 1.
On the residual vs Leverage plot the large cluster on the left is still visible. However more observations seems to be scattered which also indicates better fit.