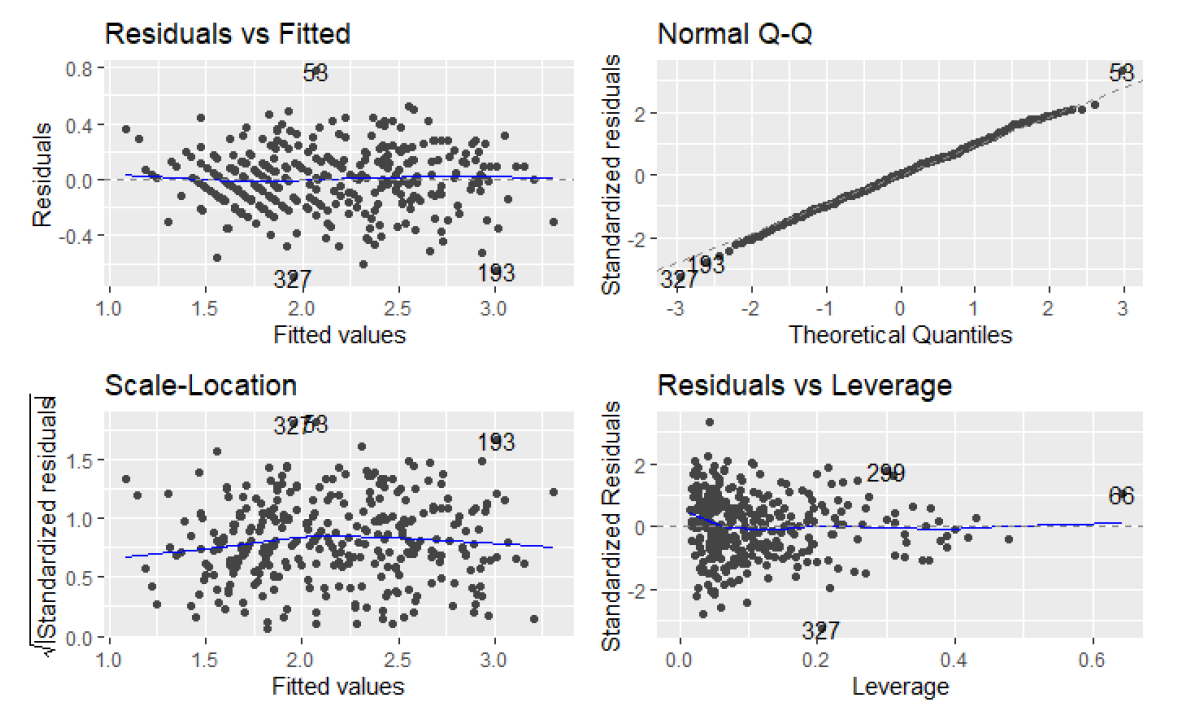
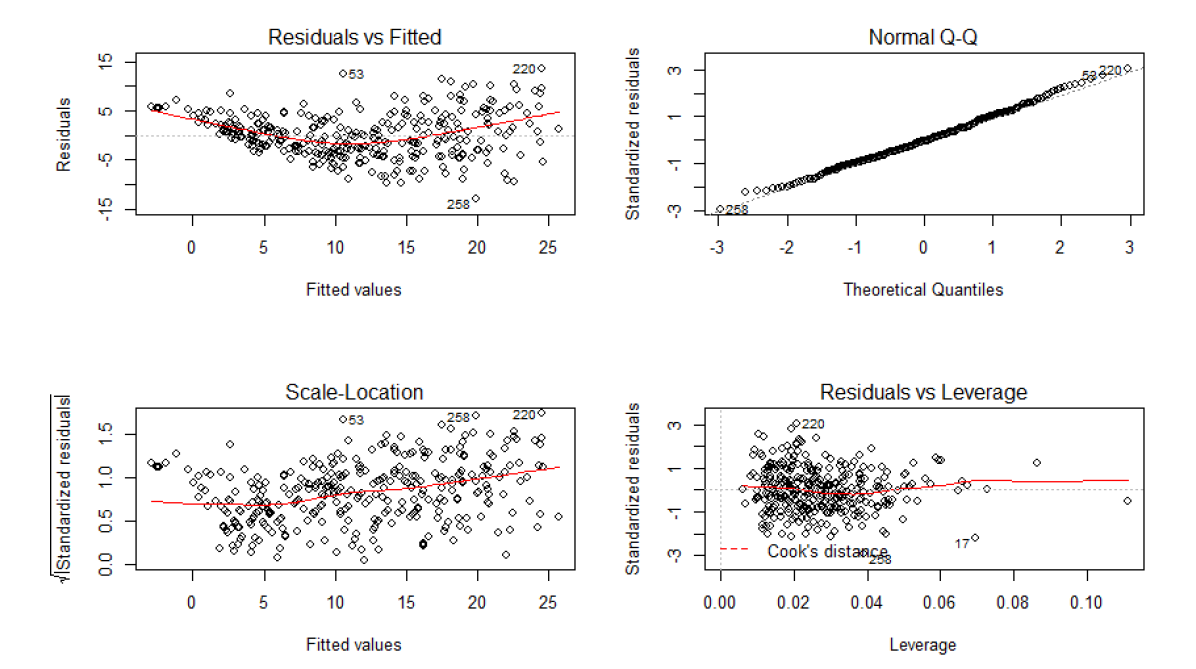
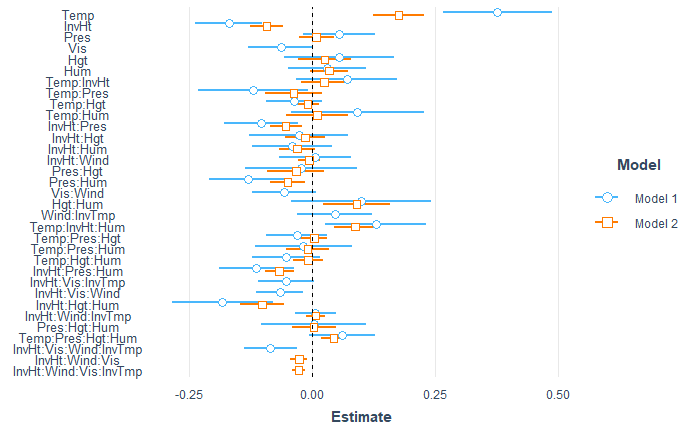
Although the coefficients seems to have very low value, which can be contraintuitive from the statistical point of view, from the empirical scope it makes perfectly sense. Our dependent variable is measured in parts per million. If we would have transformed the particles into length (or volume to be more cleared) unit scale, we would probably get them into micrometers or manometers scale compared with for example visibility, which is measured in miles.
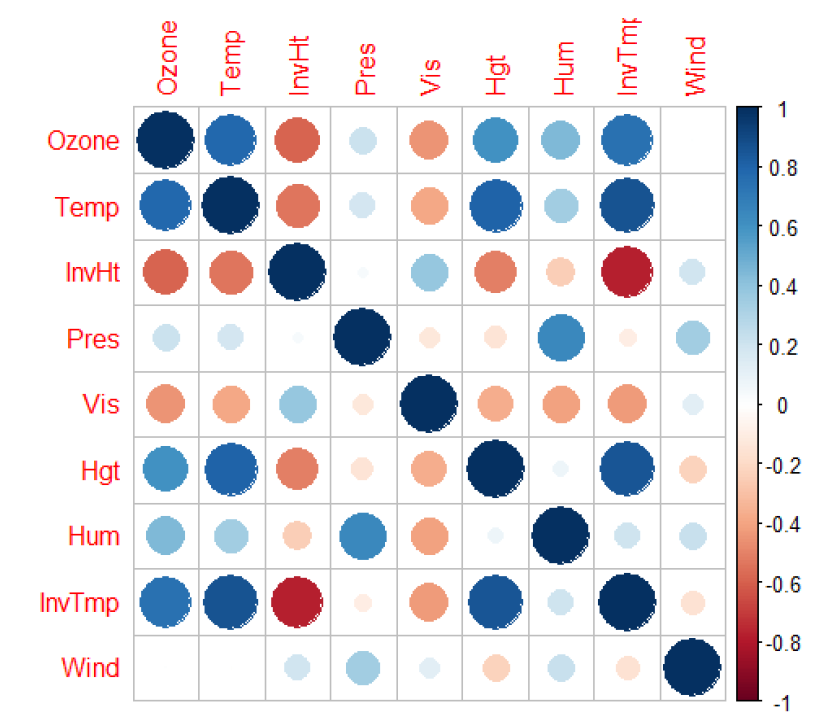
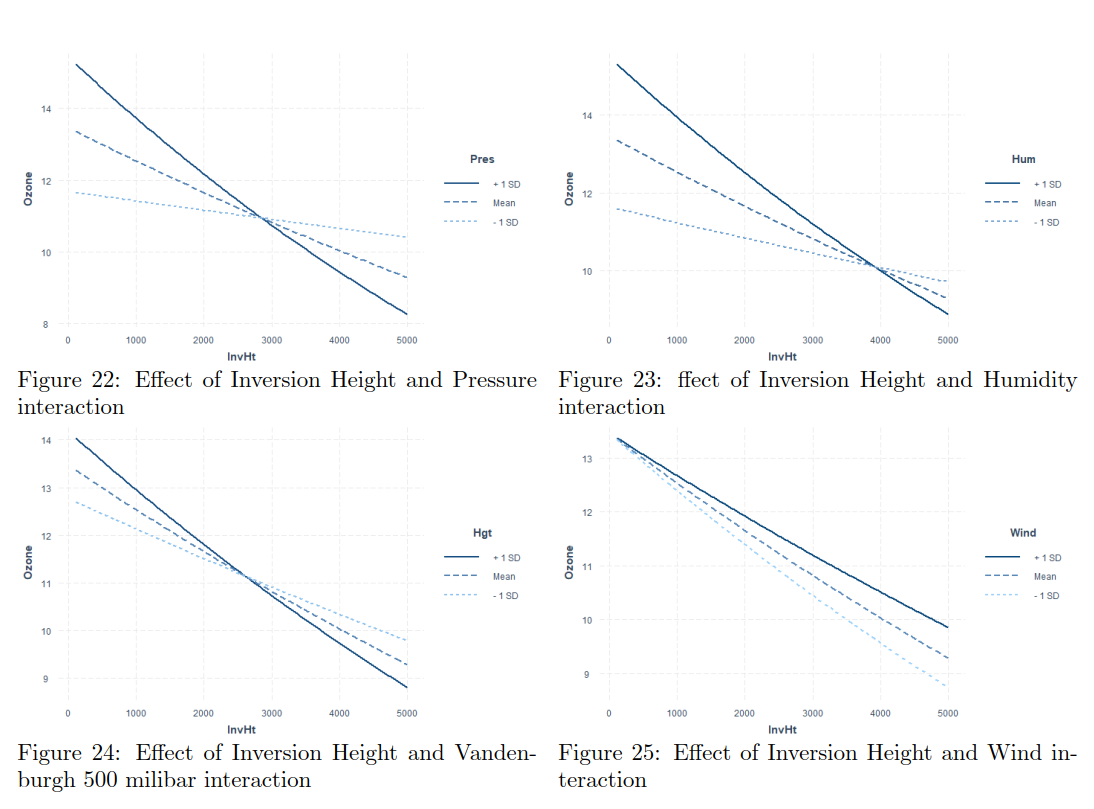
Considerieng sign of the coefficients, we can observe that additive effects without interactions (Temp, InvHt, Pres, Hgt, Hum) have all negative signs. We can see that the „strongest“ coefficient is for humidity, with value 1.091e+00. It would be easy to conclude that the humidity has the strongest effect on the ozone concentration, however particles modelling is very complex system that is very sensitive to disturbances of any kind. We can see that on modelled interactions. The coefficient with the lowest value of -2.037e-09 is for the interaction between Inversion base height, wind, visibility and Inversion base temperature, however it is still significant and we can conclude that even the tiniest increases or decreases in these variables can change the ozone concentration. The effect applies on any other interactions as well. We were surprised that in the final model, the wind speed is not significant. The intuition could deceive us that the ozone particles can be „blown away“ however it does not seems to be so easy. The wind speed seems to interacts with Inversion related variables (Inversion base height and Inversion Temperature, and also with Visibility) with more than 6 times lower values when comparing with Humidity. The weakness of the model also can be that it does not take into consideration directly effect of the air pollution. armful levels of ozone can be produced by the interaction of sunlight with certain chemicals emitted to the environment (e.g., automobile emissions and chemical emissions of industrial plants).
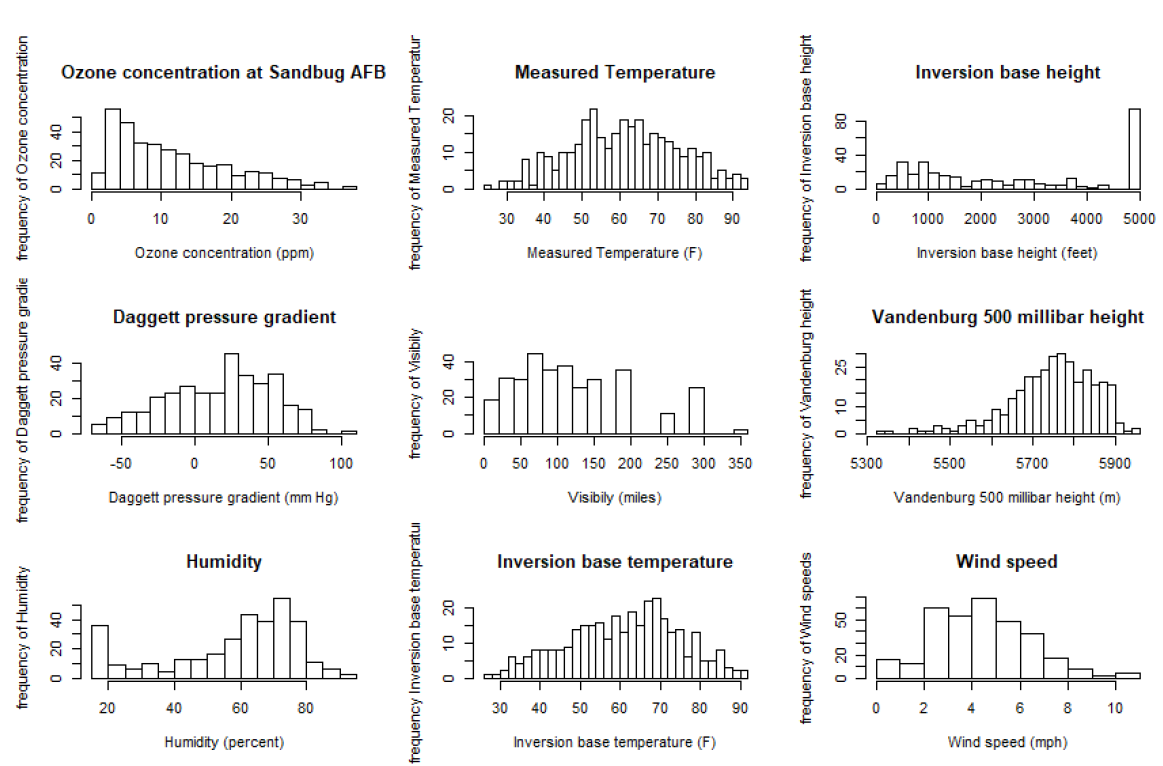
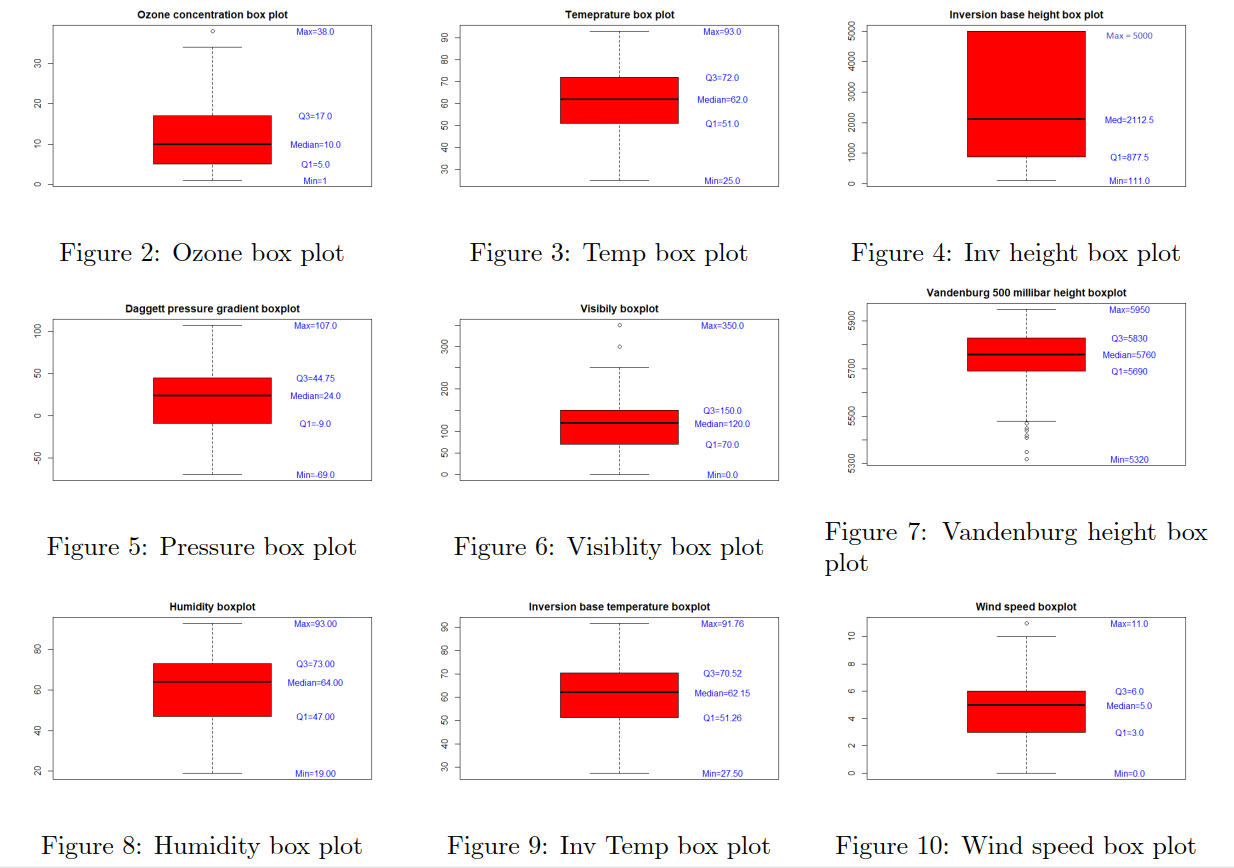
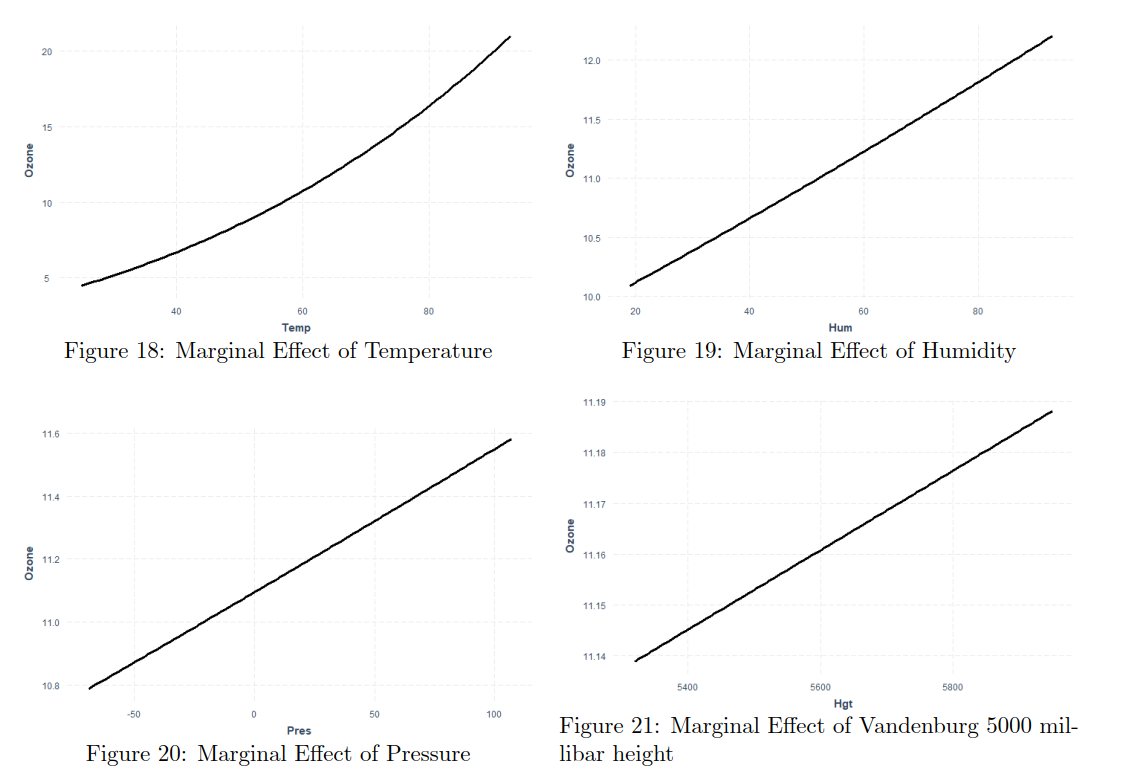
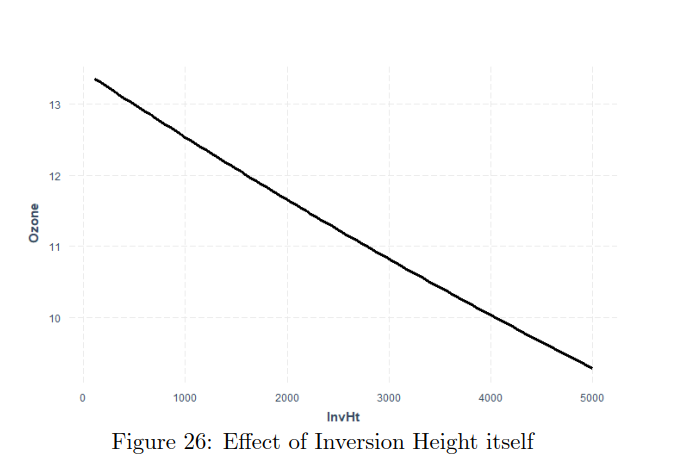
By plotting the additive effects we can observe that with Increasing Temperature, Pressure, Humidity, Vandenburg Height the ozone concentration increases. When increasing Inversion base Height Ozone concentration decreases. That makes perfect sense as An inversion traps air pollution, including ozone, close to the ground so low values of Inversion height mean that „clouds are up“ and when high then we have inversion. Therefore if we consider Inversion as the product of human activity, we can infer that air polluting increases the amount of harmful ozone particles in the air. Overall models seems to get plausible results (in terms of statistics), the weakness can be that the data are outdated (1976) and we have observations only from one measuring station, therefore we cannot infer impacts from other cities than Los Angeles.


 is the vector of response variable,
is the vector of response variable,  is vector of explanatory variables and
is vector of explanatory variables and  is vector of parameters.
is vector of parameters.
 is the i-th expected value of (E[
is the i-th expected value of (E[ ], which has to be positive,
], which has to be positive,  is the intercept and
is the intercept and  are the coefficients of predictors.
are the coefficients of predictors.
 and
and  are uncorrelated, an interaction (
are uncorrelated, an interaction ( ) might exist and impacts the correlation of the coefficients. As we have already seen, the explanatory variables have high correlations therefore the approach for checking the interactions between all the explanatory variables might not be a good approach.
) might exist and impacts the correlation of the coefficients. As we have already seen, the explanatory variables have high correlations therefore the approach for checking the interactions between all the explanatory variables might not be a good approach.
 is i-th fitted value,
is i-th fitted value,  are parameters coefficients.
are parameters coefficients.